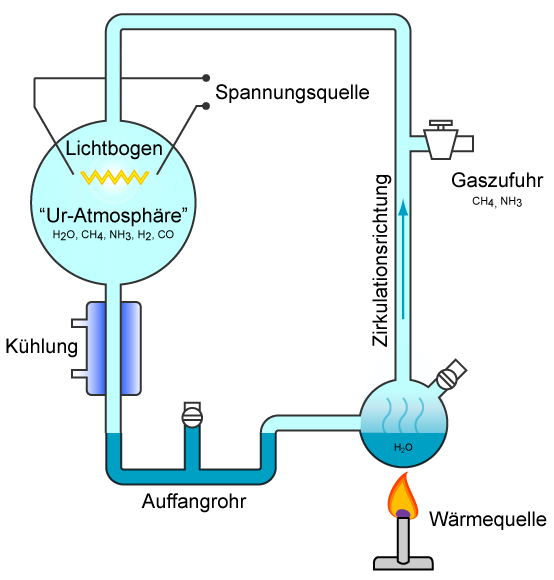
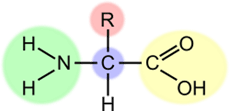
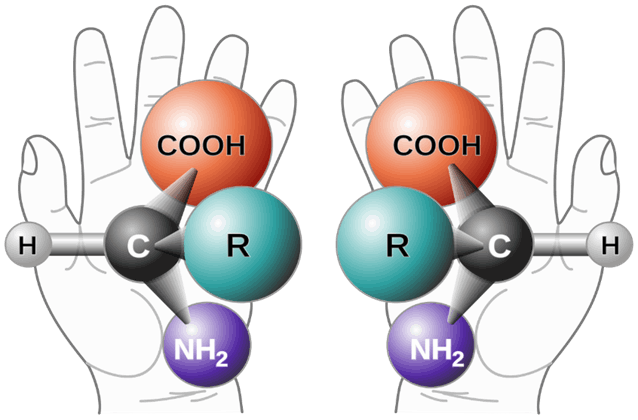
Die frühe RNA konnte aber nach Meinung der Biologen noch mehr als „nur“ Information zu codieren. Zugleich war sie fähig, die nötigen chemischen Reaktionen zu ihrer eigenen Vermehrung in Gang zu setzen.
Sie stellte also nicht nur den „Bauplan“ zur Verfügung, sondern führte zugleich auch die „Bauarbeiten“ aus. Auf diese Weise konnte sie das realisieren, was biologisch betrachtet Leben in seiner einfachsten Form ausmacht: Kopien von sich selbst erzeugen. Bewiesen ist das alles freilich nicht. Es wird aber gemäß der sogenannten „RNA-Welt-Hypothese“ so angenommen, weil sich die Entstehung des Lebens in seiner Frühphase damit nach Meinung der meisten Biologen am besten erklären lässt.
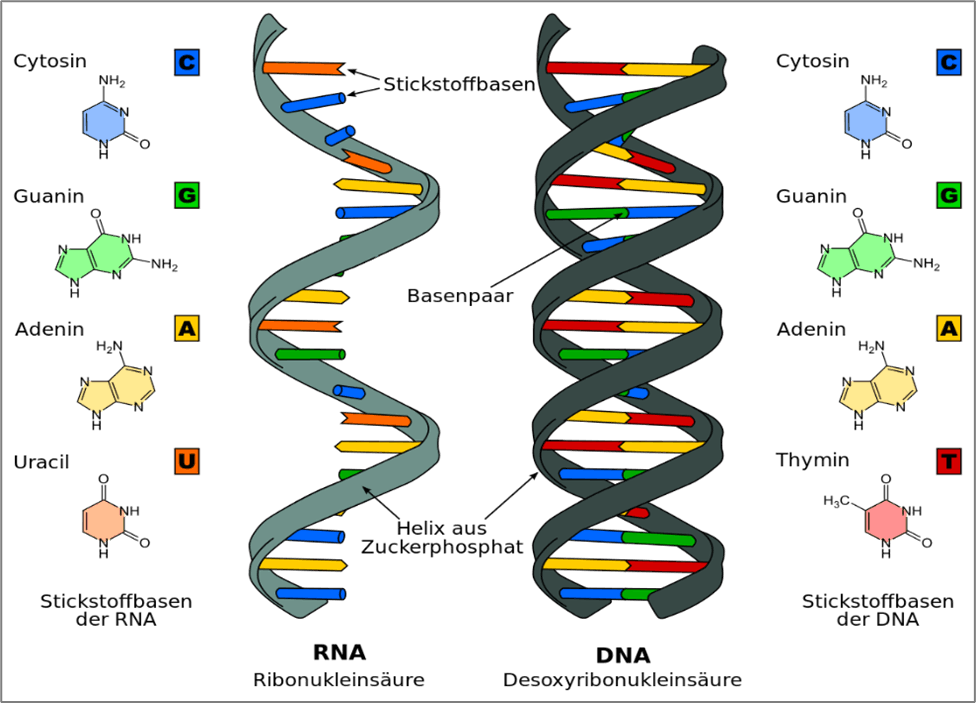
Erst viel später sollen sich infolge weiterer Evolutionsschritte komplexe Zellen gebildet haben. Die RNA ist in diesen Zellen zwar noch enthalten, die Rolle des Informationsträgers hat inzwischen aber eine andere Nukleinsäure übernommen, nämlich die Desoxyribonukleinsäure (DNA). Wie Sie auf der rechten Seite der obigen Abbildung erkennen können, besteht die DNA aus zwei spiralförmig gewundenen Seitensträngen. Sie ist stabiler als die RNA und sie kann auch mehr Information speichern.
Die DNA kann jedoch im Gegensatz zur frühen RNA den „Bauplan“, den sie zur Verfügung stellt, nicht selbst ausführen. Hierfür sind in den Zellen die Proteine zuständig. Und weil die DNA innerhalb der Zelle mit den Proteinen gar nicht in direktem Kontakt steht, braucht es einen Übermittler der Information. Diese Aufgabe übernimmt nun die RNA. So bilden die drei Bestandteile unserer Zellen eine Art zusammenwirkendes Team: Die DNA fungiert als „Architekt und Baumeister“, die Proteine als „Arbeiter“ und die RNA als eine Art „Baustellenleiter“, welcher den Arbeitern Anweisung gibt und verständlich erklärt, was der Architekt, also die DNA, von ihnen erwartet.
Nun wissen wir also, wo der „Bauplan des Lebens“ steckt (nämlich in der DNA), wie er ausgeführt wird und wie die Codierung funktioniert. Aber wie plausibel ist die Behauptung, dass sich all das zufällig so entwickelte? Wie wahrscheinlich ist es, dass sich aus einer Ursuppe von unbelebten Molekülen lange Verkettungen bildeten, die dann zufällig Sequenzen von Basen enthielten, die ausgerechnet eine Bauanleitung für sich selbst ergaben? Wenn Sie eine Buchstabensuppe umrühren und mit dem Löffel nach dem Zufallsprinzip Buchtstaben aus der Suppe herausschöpfen, wie wahrscheinlich ist es, dass die Buchstaben auf dem Löffel dann als sinnvoller Text angeordnet sind, und zwar in genau der Weise, dass der Text das Rezept für die Buchstabensuppe enthält? Wie wahrscheinlich ist es, dass ein Molekül, das seinen eigenen Bauplan codieren kann, zufälligerweise gleichzeitig auch noch dazu in der Lage ist, diesen Bauplan auszuführen, so wie die RNA-Welt-Hypothese das behauptet? Und wie wahrscheinlich ist es außerdem, dass zufällige Mutation im Laufe der Zeit zu einer immer komplexeren und dichteren Informationscodierung führte? Bei der DNA, die wie gezeigt die RNA als Informationsträger ablöste, reden wir immerhin von einer Informationsdichte, die alles übersteigt, was wir Menschen mit modernster Informationstechnologie jemals hergestellt haben. Unsere DNA kann auf kleinstem Raum mehr Daten speichern als jede Festplatte. Die Computerfachzeitschrift „Computer Weekly“ rechnete kürzlich vor:
„Der Abstand von zehn DNA-Basenpaaren ist 3,4 Nanometer lang und hat einen Durchmesser von 2 nm. Jedes Basenpaar ist eine Kombination aus zwei Nukleotiden: Adenin (A) und Thymin (T), oder Cytosin (C) mit Guanin (G). Wenn jedes Paar ein Bit repräsentiert, zum Beispiel AT oder TA als „0“ und CG oder GC als „1“, könnte ein DNA-Strang denkbarerweise 10 Bits pro 6,8 nm2 enthalten. Mit anderen Worten: Die Informationsdichte der DNA beträgt 1,47 Terabit/mm2. Das ist mehr als das 800-fache der Dichte von Festplatten. Bedenkt man, dass ein mikroskopisch kleines menschliches Genom drei Milliarden Basenpaare enthält, die in jeder Zelle fest verwoben sind, sind die Möglichkeiten zur Speicherung von DNA-Daten enorm.“ (Marko, Kurt: Basiswissen: DNA-Datenspeicher und dessen Nutzung, in: Computerweekly.de vom 7. Juli 2021)
Kein Wunder, dass IT-Experten schon längst daran forschen, kommerziell nutzbare Speichermedien zu entwickeln, die auf biologischer DNA basieren. Schauen Sie sich hierzu gerne den nachstehend verlinkten Rückblick auf das High-Tech-Forum der Bundesregierung aus dem Jahr 2021 an, bei dem Biologen und Informatiker gemeinsam über die Chancen und Verfahren zur Speicherung digitaler Daten auf der DNA austauschten.